Under the Hood
A practical view of the infra-research pipeline that powers how Juris IQ converts legal questions into grounded, reviewable outputs.
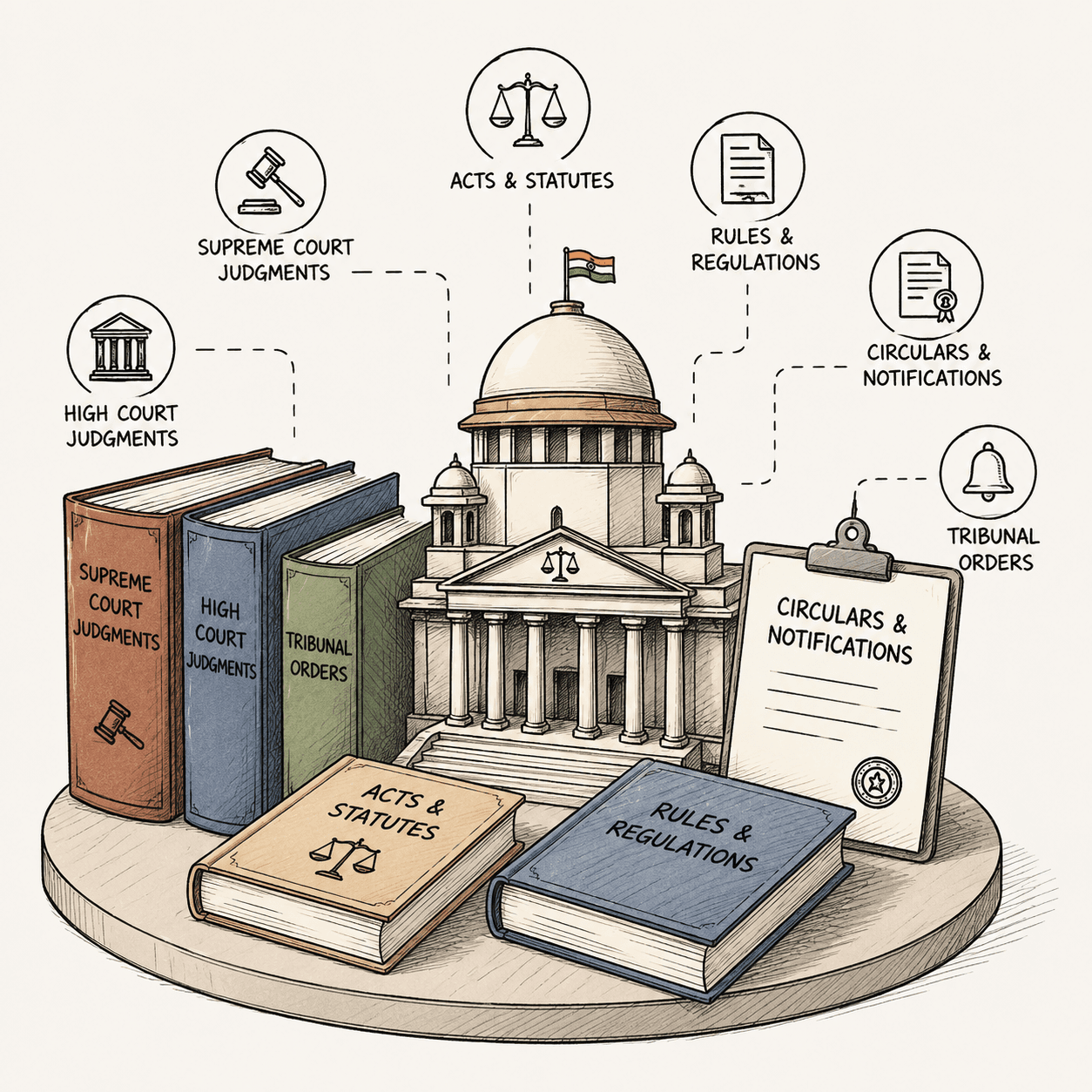
Indian Legal Corpus
The trusted foundation of JurisIQ.
Every AI response begins with a comprehensive collection of Indian legal sources, ensuring research is built on authoritative and up-to-date information.
Includes
- Supreme Court Judgments
- High Court Judgments
- Tribunal Orders
- Acts & Statutes
- Rules & Regulations
- Circulars & Notifications
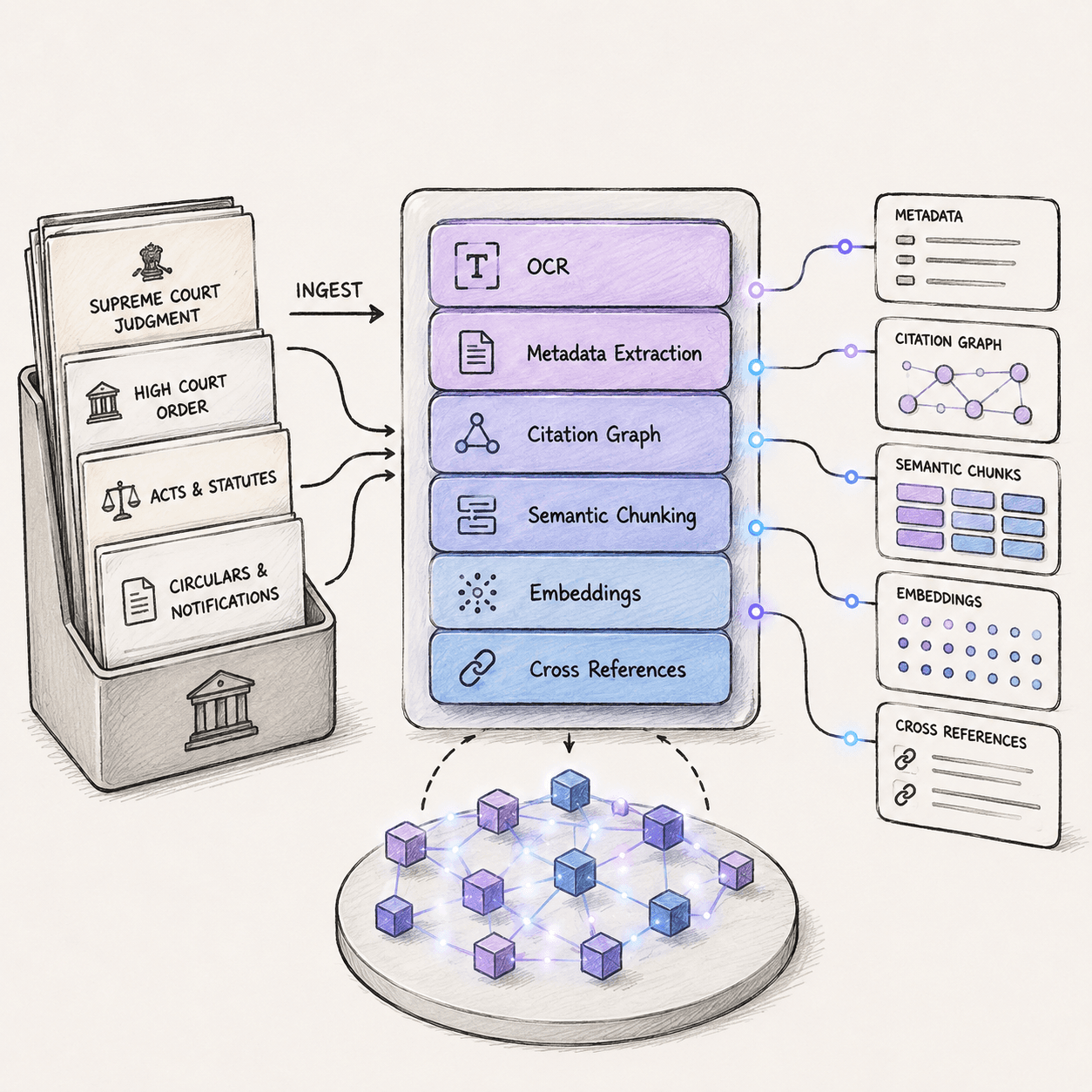
Legal Intelligence
Transforming legal documents into structured knowledge.
Raw PDFs and court records are processed to extract relationships, metadata, and semantic meaning, making every document instantly searchable and AI-ready.
Processing Pipeline
- OCR
- Metadata Extraction
- Citation Graph
- Semantic Chunking
- Embeddings
- Cross References
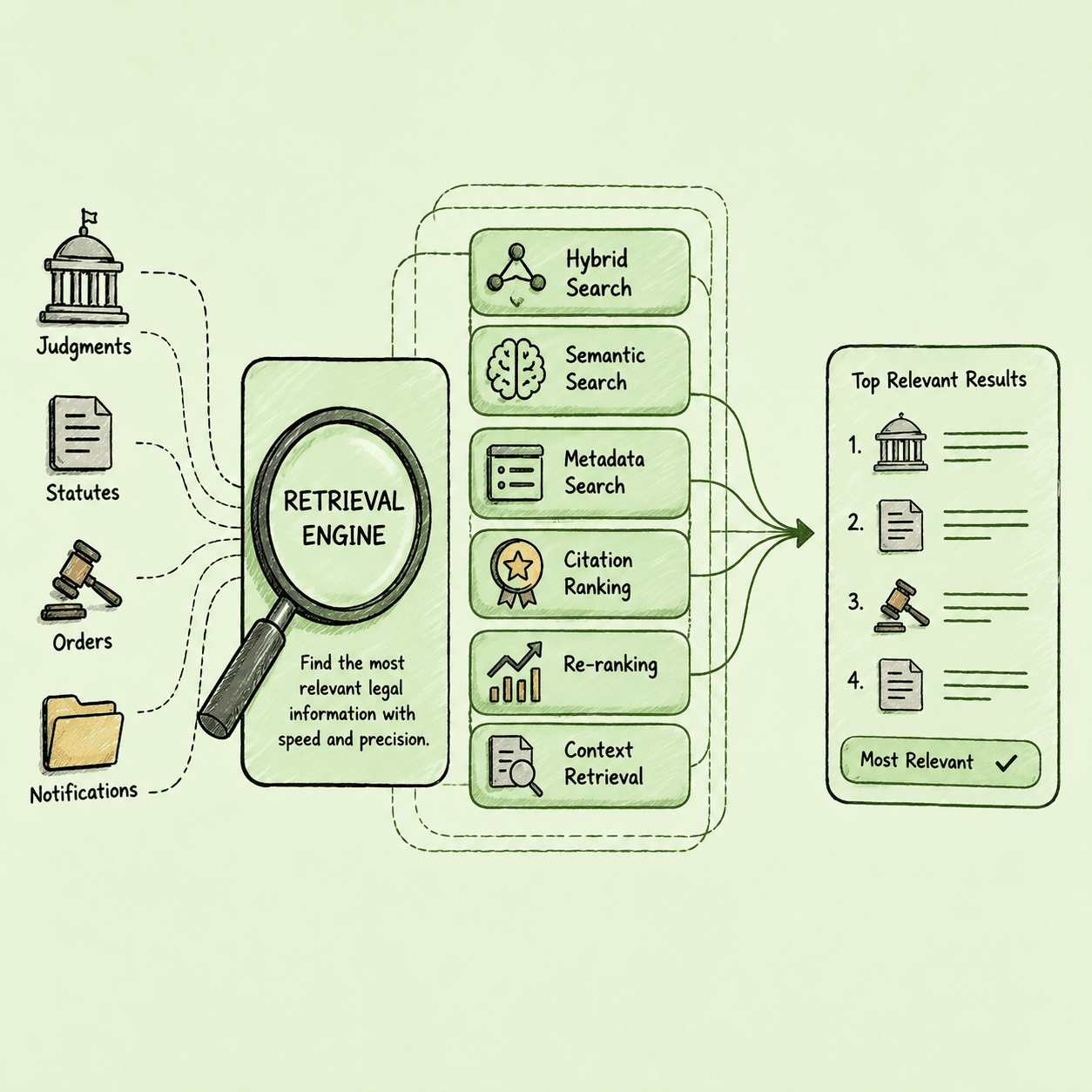
Retrieval Engine
Finding the most relevant legal information with precision.
Instead of relying on keyword search alone, JurisIQ combines multiple retrieval strategies to surface the most relevant authorities for every legal query.
Search Capabilities
- Hybrid Search
- Semantic Search
- Metadata Search
- Citation Ranking
- Re-ranking
- Context Retrieval
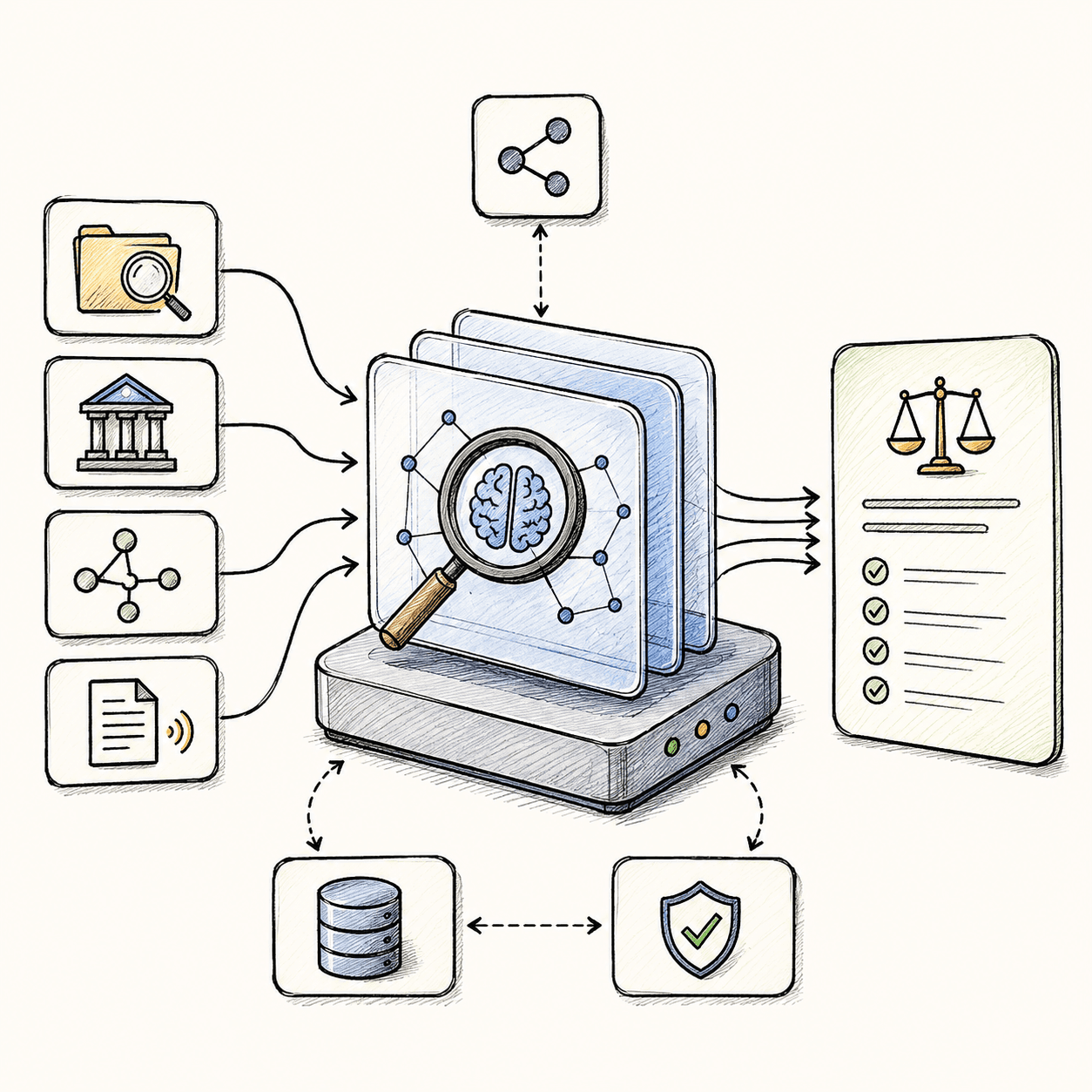
AI Research Engine
Turning retrieved information into reliable legal intelligence.
Relevant authorities are assembled into context, validated, and reasoned over before generating grounded, citation-backed legal responses.
AI Pipeline
- Context Assembly
- Prompt Orchestration
- Grounded Generation
- Legal Reasoning
- Memory
- Validation
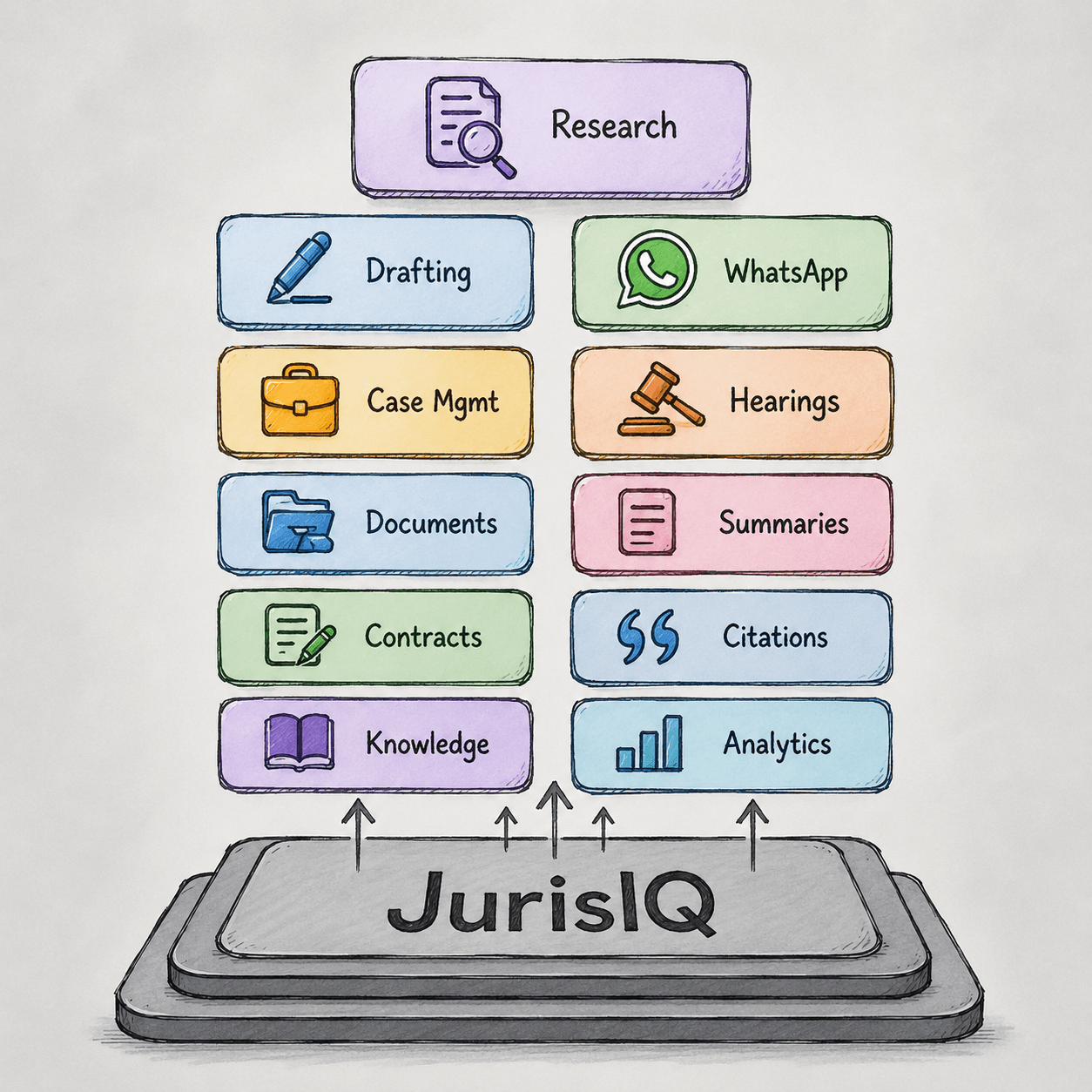
JurisIQ
Your unified AI workspace for legal practice.
Research, drafting, case management, and collaboration come together in one intelligent workspace designed for modern lawyers.
Everything in one place
- AI Legal Research
- Drafting Assistant
- WhatsApp Assistant
- Case Management
- Hearing Tracking
- Document Workspace
- Contract Review
- Knowledge Base
- Analytics & Insights

Grounded Answers
Every response is generated from verified legal sources, not assumptions.
Multi-Layer Search
Combines metadata, semantic understanding, citations, and contextual ranking to retrieve the most relevant authorities.
Explainable Research
Every answer includes supporting judgments, statutes, and legal references so researchers can verify the reasoning.
Built for Indian Law
Designed specifically around Indian courts, statutes, tribunals, and litigation workflows.
Every answer is traceable. Every citation is verifiable. Every insight begins with trusted legal data.